Introduction
Lookaside lists can be used to improve performance in some cases. In this project you will simulate a lookaside lists, and collect and display performance statistics. It is an artificial problem that will demonstrate lookaside lists.
Note: There are Python modules that can be use to collect performance statistics. Examples are: Be sure to search the web for more information, examples, and modules.
Problem Description
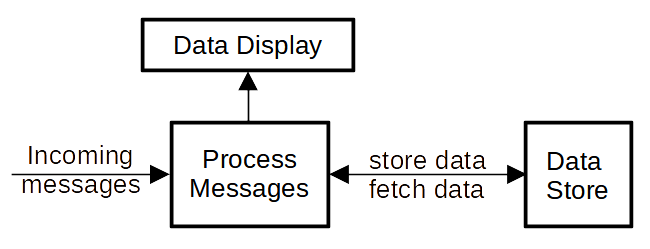
- stored data consists of records containing several fields and a unique ID.
- each incoming message refers to a single record ID for some type of action.
- there are four types of incoming messages (actions)
- add a data record
- modify a data record's field(s)
- delete a data record
- display a data record's field(s)
- the data store is used by other processes/systems creating some amount of delay/latency.
- the data store was optimized for data store and not data fetch.
- to update a record's field(s) requires:
- fetch a copy of a record from the data store
- modify the record
- send the record back to the data store
- modify messages are by far the most common message type.
- modify messages come in bursts. several messages in a row can refer to the same record ID.
- modify bursts can be 2 to 8 messages.
- Messages are randomly distributed in the incoming message stream except for modify bursts.
Note: I worked on a project that was similar to the problem described above. Implementing a simple (1 deep) lookaside list significantly improved throughput and reduced CPU usage.
The Data Store
I suggest you use one of the memory/file databases as your "data store" instead of creating your own. There are several that are available. Using one will simplify your code and be more realistic.
DBM is an example of one:
dbm — Interfaces to Unix "databases"
Python – Database Manager (dbm) package
Python Data Persistence - dbm Package
Python has a built-in persistent key-value store
code example from the web
My DBM documentation/Cheatsheet
Project #1
This project will demonstrate the use of a 1 deep lookaside list and how/if it can improve efficiency by collecting and displaying performance statistics.
Notes:
Design
- randomly generate incoming messages
- modify messages can come in bursts
(Not all at one time but all related to the same record ID) - Message mix is:
- 80% modify messages
- 10% display messages
- 5% delete messages
- 5% add messages
- build a delay into the record fetch (try 0.001 sec?)
- create a 1 deep lookside list
(1 deep means a lookaside list of one record) - turn the use of a lookaside list on/off
- collect and display performance statistics
- messages will be CSV strings
- the first field is the action
- the second field is the record ID
- the third, fourth, ... fields contain data
- a single integer data field will probably be enough to for testing
Which performance statistics should be collected and displayed?
I suggest collecting execution time for 2,000 runs of 2,000 messages to start with. Modify this until you get reliable statistics. Remember to use the same mix and order of messages. Also, collect record message type statistics to verify the record stream mix.
Actions Base On Message Mix Assumptions
| Action | Description |
|---|---|
| add a record | The record is added to the data store and also put in the lookaside list.
If the record already exists in the data store, generate an error.
(If the lookaside list is more than 1 deep, replace a random record
or the oldest record. This depends on the expected message mix.) |
| modify a record | Before fetching a copy of a record from the data store, see if it is
in the lookaside list. If not, fetch the record from the data store into the lookaside list. Modify the record in the lookaside list and send it to the data store. If the record does not exists in the data store, generate an error. (If the lookaside list is more than 1 deep, replace a random record or the oldest record. This depends on the expected message mix.) |
| delete a record | Delete the record from the data store, and the lookaside list. |
| display a record's fields |
If the record is not in the lookaside list,
fetch a copy from the data store.
Display the record's field(s). Do not modify the lookaside list. (This assumes there will not be a need for this record right away.) |
Would it be appropriate for each message type have its own lookaside list?
Project #2
Allow the user to vary the size of the lookaside list, the fetch delay/latency, the mix of messages, etc.
Plot the performance statistics.
Questions
1. Why are we only interested in the "fetch record" latency?
We want the data store to contain the most up-to-date data as possible. Thus the faster we can update the data store, the more up-to-date it is.
The assumption is that the read/write code is as fast as possible and can not be improved. Faster hardware is a possibility but that decision is up to others.
The lookaside list can effect the apparent latency in "data store" reads because (in some circumstances) we do not perform a read. The data is already available in the lookaside list.
2.What is important about the incoming message mix?
It is important to understand the incoming message mix. For example, if the mix is truly random, the use of a lookaside list would have little effect on performance. Because the modification messages are "clustered", we get more-bang-for-our-buck by using a lookaside list.
3.Why collect statistics, etc?
4. Isn't a lookaside list just like caching?
Yes.
5. Where is a lookaside list used?
Lookaside lists (caches) are used in high performance situations. For example, operating systems and hardware. (And of course this demo.)