Introduction
Note: You can ignore all of the math "stuff" if you want to. The project is to count words and "eyeball" plot the results. (Find all of the unique words and count them.)
In mathematical statistics, the concept has been formalized as the Zipfian distribution: a family of related discrete probability distributions whose rank-frequency distribution is an inverse power law relation.
Zipf's Law: In a collection, the nth common term is 1/n times of the most common term. E.g. the 5th most common word in English occurs nearly 1/5 times as often as the most common word.
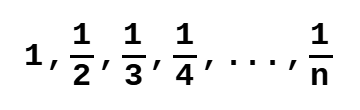
See examples HERE
 .
.
Project #1
Find all of the unique words in a (long) text document and count them. Plot the theoretical zipf distribution vs the word counts distribution. Does it approximate a Zipf distribution?
Remove punctuation and convert words to upper or lower case for counting? Assume only ASCII characters?
Project #2
Do project #1 except using the length of words. Plot the theoretical zipf distribution vs the word lengths distribution. Does it approximate a Zipf distribution?
Possible Text Files For Testing
Declaration of Independence
United Sates Constitution
Your favorite story or book
Screen scrape a long HTML document.
Docs
Zipf's Law (Wikipedia)
Analog Science Fiction and fact Magazine Guest Editorial
- Date: May/June 2024
- Title: Zipf’s Lottery and Big Rocks From Space
- Author: Howard V. Hendrix
- Website: www.analogsf.com